[세미나 발표 3] 머신러닝 세미나 3팀 - Transfer Learning(전이학습)
머신러닝 세미나가 10월 12일 어느 새 마지막으로 접어들고, 프로젝트가 남았습니다.

이 날 3팀은 Transfer Learning, 즉 전이학습에 대해 발표해주셨는데요.

위와 같은 순서로 발표해주셨습니다.
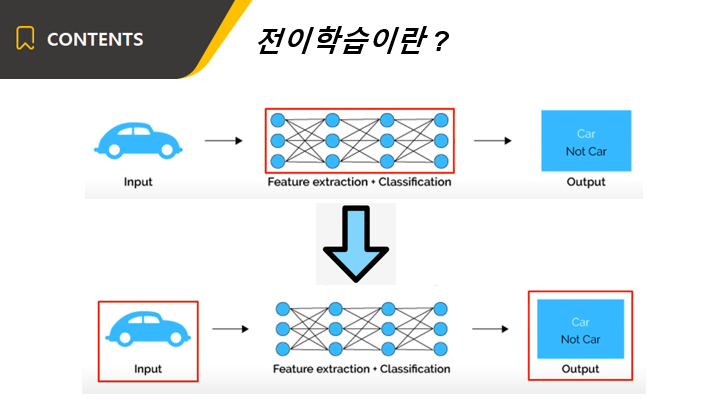
보통 일반적인 신경망은 먼저 가중치 파라미터를 랜덤으로 초기화 한 후 그 다음 입력이 주어지면 정답을 맞추도록 훈련합니다.
이렇게 학습이 끝난 가중치가 바로 신경망의 지능입니다.
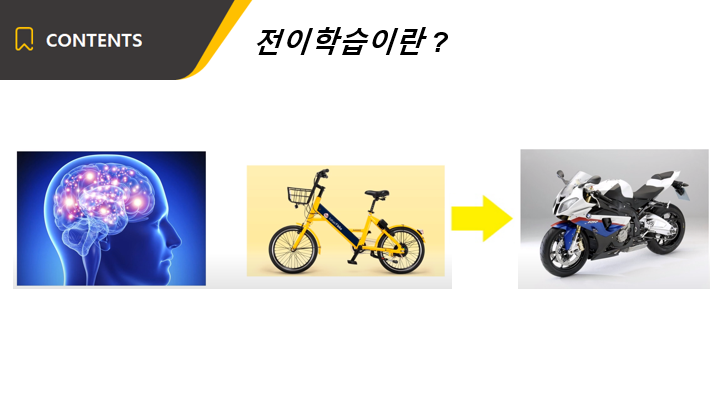
인간의 경우에는, 이미 자전거를 탈 수 있다고 가정 했을 때 오토바이 타는 법을 새로 배운다면 뇌를 초기화하고 처음부터 다시 시작하지 않습니다.
자전거를 타는 방법 뿐만 아니라 수십년 동안 쌓아왔던 경험을 기반으로 학습합니다.

이와 같이 인공지능들이 사람처럼 이전 지식을 활용하여 새로운 지식을 배우는 방법을 전이학습이라고 합니다.
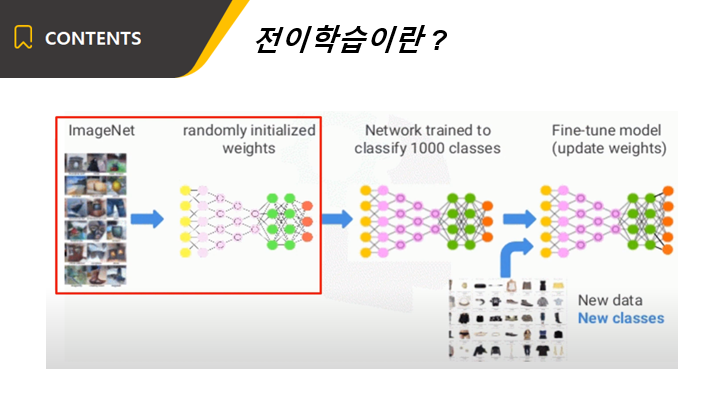
전이학습이 처음 사용된 곳은 이미지 인식이었습니다. 먼저 대량의 데이터로 사전훈련을 합니다.
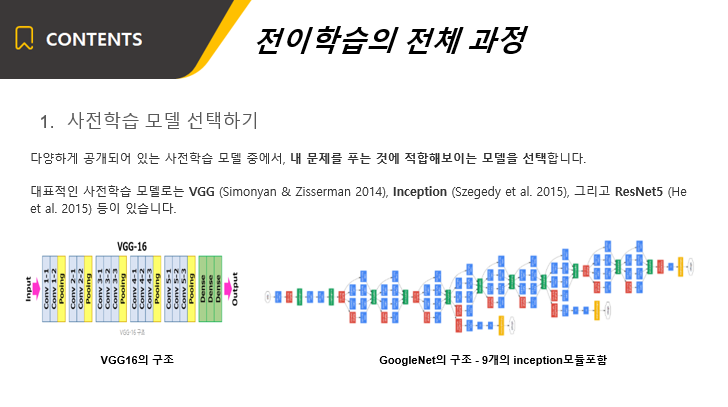
전이학습을 하기 위해서는 어떤 모델 구조를 사용할 것인지를 먼저 선정해야 합니다.
이미지를 예시로 들면, 이미지에 대한 모델로써 VGG, Inception, ResNet 등이 있습니다.

그리고나서 해당 모델을 어떤 데이터셋으로 학습을 시켰는지 알아야 합니다.
여기서 작은 데이터셋의 크기는 경험적으로 1000개 이하의 이미지 데이터셋 정도를 말합니다.
데이터셋의 유사성에 대해서는 상식의 선에서 생각해볼 수 있습니다.
예를 들어, 고양이와 강아지를 분류해야 하는 상황이라면, ImageNet 모델은 이미 고양이와 강아지에 대해 학습했기 때문에 내 문제와 유사하다고 할 수 있지만, 암세포를 구분해야 하는 상황이라면, ImageNet은 유사한 데이터셋을 학습한 모델이라고 볼 수 없을 것입니다.

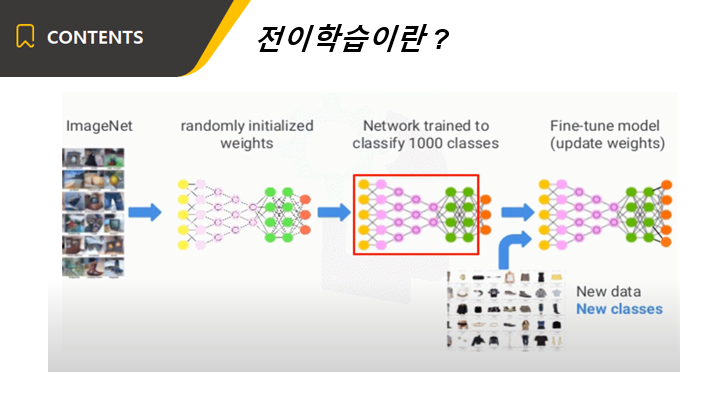
그리고나서 모델이 학습한 기존 데이터와, 우리가 학습하려는 데이터가 다르기 때문에 우리의 데이터에 맞게 변경하는 과정을 거쳐야 합니다.
예를 들어, 이전에 썼던 알고리즘이 개와 고양이를 구분하는 예제였고, 우리의 데이터가 말과 소를 구분하는 예제라고 합시다.
알고리즘의 구조는 그대로 가지고 오고, 마지막에 개와 고양이를 예측하는 부분을 말과 소를 예측하는 부분으로 바꾸어주면 됩니다.

이를 다양한 라이브러리로 구현할 수 있습니다.

전이 학습의 사용 예제로써, 자연어처리 문제가 있습니다.
대표적으로 구글에서 쓰는 BERT라는 모델이 있습니다.

이는 단어들을 학습을 시킨 후 목적에 맞게 사용을 하기 위한 모델입니다.
몇 십만개의 단어로 학습을 시킨 후, 최종적으로 fine-tuning을 통해 예측하려는 문제에 적용을 한다고 합니다.
이로써 전이학습에 관한 설명을 마쳤습니다.
세미나에 힘써주신 머신러닝 3팀 모두 감사드립니다 :)