[세미나 발표 3] 머신러닝 세미나 2팀 - Recurrent Neural Network(RNN)
머신러닝 세미나가 10월 12일 어느 새 마지막으로 접어들고, 프로젝트가 남았습니다.

이 날 2팀은 Recurrent Neural Network(RNN)에 대해 발표해주셨는데요.

위와 같은 순서로 발표해주셨습니다.

RNN은 가변적인 시퀀스 데이터를 모델링하기 위해 등장하였습니다.
이 때 시퀀스란 음악, 동영상, 시를 예로 들 수 있는데 음악은 음계들의 시퀀스, 동영상은 이미지의 시퀀스, 시는 단어의 시퀀스라고 할 수 있습니다.
기존의 뉴럴 네트워크 알고리즘은 이미지처럼 고정된 크기의 입력을 다루는 데 탁월했지만 가변적인 데이터를 모델링하기에는 적합하지 않아서 RNN이 등장하게 되었습니다.

가변적인 데이터를 다루기 위해 등장한 RNN은 정적인 데이터를 입력받고, 이러한 데이터가 입력될 때마다 자신의 기억을 수정합니다.
입력을 모두 처리하고 난 후, 남겨진 기억은 시퀀스 전체를 요약하는 정보가 되고, 이런 과정이 반복되기 때문에 Recurrent(순환적인) Neural Network 라는 이름이 붙었습니다.
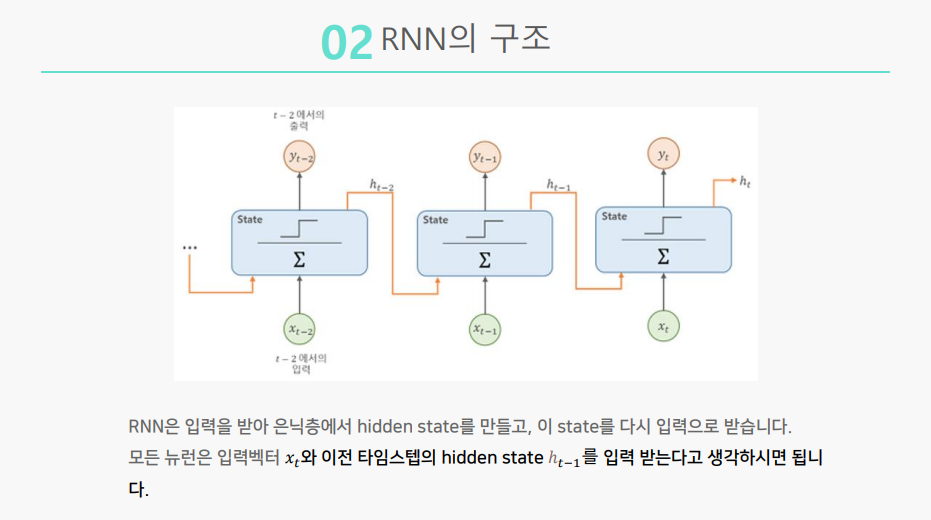
RNN의 구조는
위의 이미지에서 초록색 동그라미는 입력, 파란색 상자는 기억, 빨간색 동그라미는 출력으로 간주하면 됩니다.
입력이 들어와서 기억이 만들어지고, 다른 입력이 들어오면 기존의 기억과 방금 들어온 입력이 합쳐져 새로운 기억이 만들어집니다.

더 자세히 살펴보면, 은닉층은 기억층으로, 은닉층의 활성함수는 하이퍼블릭 탄젠트를 이용하여 구현됩니다.

RNN의 사용 예시를 살펴보겠습니다. 그 전에, RNN의 종류를 구분하면
one to many, many to one, many to many, many to many가 있습니다.
참고로 one to one이 없는 이유는 고정크기 입력 고정크기 출력이므로 순환적인 부분이 없어 RNN에 속하지 않기 때문입니다.

첫번째 예시는 Image captioning입니다.
이미지라는 고정 크기 입력과 문장이라는 시퀀스 출력으로 one to many에 해당됩니다.

두번째 예시는 translating machine으로, 번역기입니다.
해당 모델은 문장이라는 시퀀스 입력과 문장이라는 시퀀스 출력을 갖고 있기 때문에 many to many에 해당됩니다.
RNN의 한계에 대해서 알아보겠습니다.

RNN은 최근의 정보들은 활용함으로써 해결 가능한 문제에는 좋은 성능을 보이지만, 긴 시퀀스에서 전체 문맥을 고려하는 경우에는 과거 시점의 정보를 잘 반영하지 못합니다.
신경망이 곱하기 연산을 기반으로 만들어져 있기 때문에, 미적값이 1보다 조금만 커도 gradient 값이 발산하게 되고 1보다 조금만 작아도 gradient 값이 소실하게 됩니다.
이 때문에 여러 time step이 떨어진 곳에서는 gredient가 전달되지 못하고 현재 task에 아무 도움이 되지 못합니다.
이를 장기 의존성 문제이라고 합니다. 이는 은닉층의 과거 정보가 마지막까지 전달되지 못하는 상황을 의미합니다.
장기 의존성 문제를 보완한 뉴럴 네트워크를 LSTM이라고 합니다.
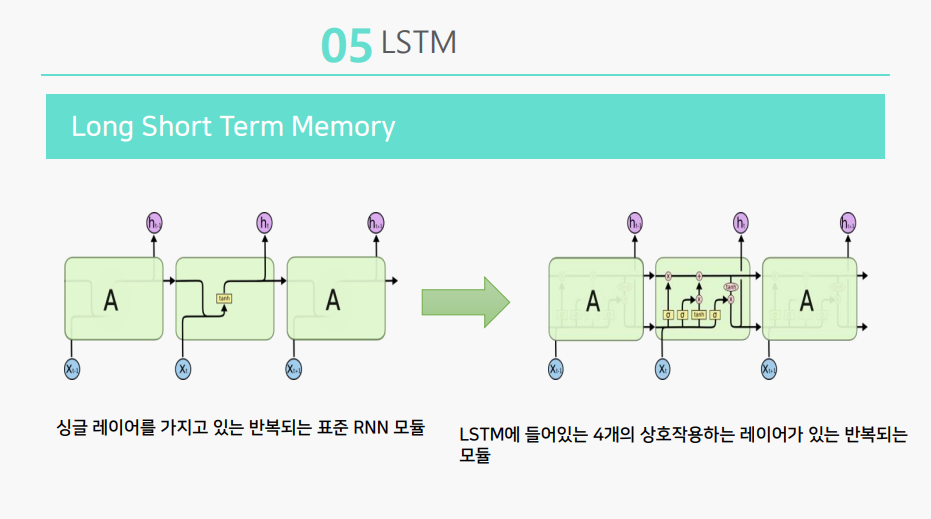
LSTM은 표준 RNN모델과 다르게, 은닉층에 상호작용하는 네 개의 레이어가 존재합니다.
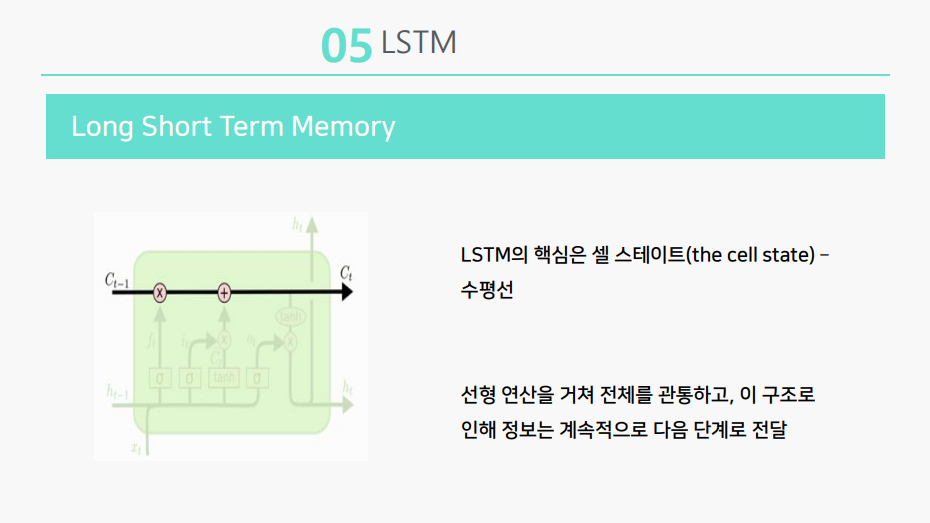
LSTM의 핵심은 셀 스테이트의 수평선인데, 셀 스테이트는 선형 연산을 거쳐 전체를 관통하고, 이 구조로 인해 정보는 계속적으로 다음단계로 전달됩니다.
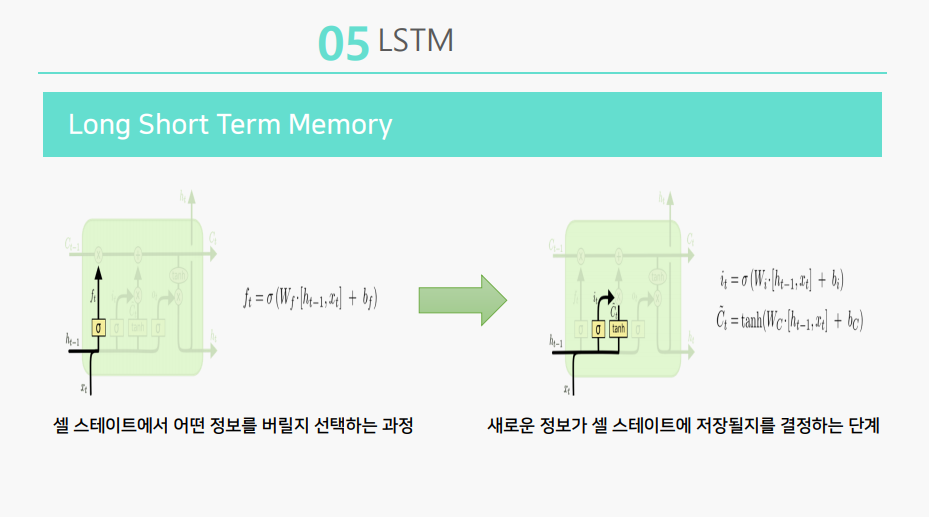
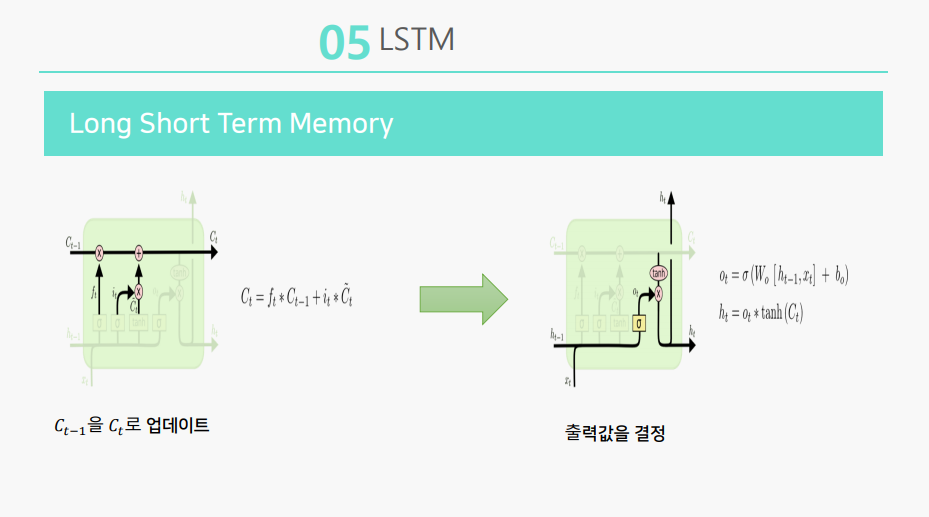
첫 번째 레이어에서는 어떤 정보를 버릴 지 선택하고
두 번째 레이어에서는 어떤 정보가 저장될 지 결정하고
세 번째 레이어에서는 업데이트하며
네 번째 레이어에서는 출력값을 결정합니다.

LSTM의 장점과 단점입니다.

참고로 LSTM의 속도 문제를 보완한 뉴럴 네트워크로 GRU가 등장했다고 합니다.

이로써 RNN에 관한 설명을 마쳤습니다.
세미나에 힘써주신 머신러닝 2팀 모두 감사드립니다 :)